
今回から複数回に分けて、Professional Cloud Data Engineer認定取得するために、私が勉強した内容をアウトプットしていきます。
今回は、K-means、BigQuery ストリーミング挿入、Cloud SQLのユースケース、Dataflowパイプラインの停止方法、Dataflowパイプライン更新について説明します!
ぜひ、最後までご覧いただけると嬉しいです!
K-means
K-meansとは?
K-meansは、機械学習の中でも「教師なし学習」と呼ばれる手法の一つで、データを自動的にグループ分け(クラスタリング)するためのアルゴリズムです。
K-meansの目的
K-meansの目的は、たくさんあるデータを、似たもの同士でグループ(クラスター)に分けることです。
たとえば、「このデータはこのグループ」「あのデータは別のグループ」といった具合に分けます。
それぞれのグループには「中心点(セントロイド)」があり、この点を基準にデータが分類されていきます。
K-meansの基本的な考え方
K-meansでは、データをいくつかのグループに分けたいときに使います。各データは「一番近い中心点」にくっつくようにグループ分けされます。
「近さ」は、よく使われる「ユークリッド距離」(2点間の直線距離)で計算されます。
K-meansアルゴリズムの流れ(ステップ・バイ・ステップ)
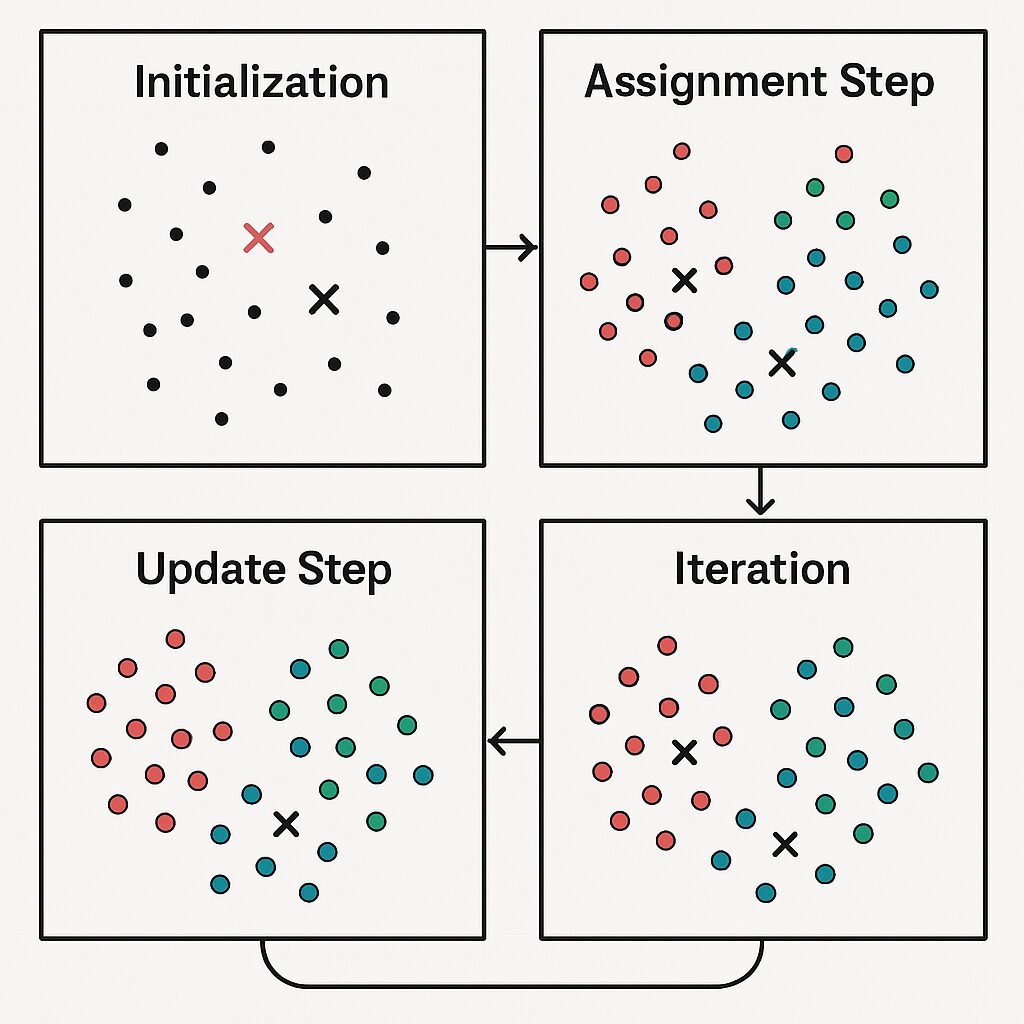
K-meansは、以下のような手順を繰り返して、データを自然な形でグループ分けしていきます。
1. 初期化(Initialization)
- まず、いくつのグループ(k個)に分けるかを決めます。
- 次に、最初のグループの中心点(セントロイド)をランダムに決めます。
2. 割り当て (Assignment Step)
- すべてのデータに対して、「どの中心点(セントロイド)が一番近いか」を計算します。
- 各データを、その一番近い中心点(セントロイド)が属するグループに割り当てます。
3. 更新 (Update Step)
- 各グループに属するデータの平均値をとって、新しい中心点(セントロイド)の位置を決めます。
※この「平均(mean)」がK-meansの名前の由来です。
4. 繰り返し (Iteration)
- ステップ2(割り当て)とステップ3(更新)を繰り返します。
- 以下のような条件のいずれかが満たされると終了します。
- 中心点(セントロイド)の位置がほとんど変わらなくなった
- データのグループ分けが変わらなくなった
- 決められた回数まで繰り返した
K-meansを使うときのポイント
- kの値を事前に決める必要がある
- グループの数(k)を先に決める必要があります。
- kが多すぎたり少なすぎたりすると、うまく分けられません。
- 「エルボー法」や「シルエットスコア」といった方法を使って、適切なkを探します。
※エルボー法:クラスタ数を変化させたときのSSE(誤差平方和)の減少をグラフ化し、SSEの減少が緩やかになる「ひじ(エルボー)」の位置を最適なクラスタ数とする手法です。
※シルエットスコア:各データがどれだけ適切なクラスタに属しているかを0〜1の値で評価する指標で、スコアが高いほどクラスタリングの妥当性が高いとされます。
- 初期の中心点によって結果が変わる
最初に決める中心点(セントロイド)の場所が違うと、最終的なグループ分けも変わってしまいます。そのため、何回か試して、良い結果を選ぶのが一般的です。 - 丸い形のグループに向いている
K-meansは、丸くて均等なグループを作るのが得意です。細長いグループや、密度がバラバラなグループにはあまり向いていません。 - 外れ値に弱い
明らかに他と違うデータ(外れ値)があると、中心点がずれてしまうことがあります。事前に外れ値を取り除くなどの対策が必要です。 - 大規模データに強い
計算がシンプルなので、大量のデータにも比較的早く処理できます。 - 特徴量のスケーリングが重要
特徴量(データの各項目)の単位がバラバラだと、距離の計算に影響が出てしまいます。事前に「標準化」や「正規化」をして、スケールを揃えておくと良いです。
K-meansの活用例
K-meansはさまざまな分野で使われています。たとえば、
- 顧客のグループ分け(セグメンテーション)
購入履歴やWebの行動データをもとに、似たお客さんをグループ化し、マーケティングに活用。 - 異常検知
どのグループにも属さない、あるいは中心点から遠すぎるデータを異常として検出。 - 文書の分類
単語の出現頻度などから、似た内容の文書をグループ化。 - 画像圧縮・色の数を減らす
画像の色を代表的なk色に減らして、データ量を小さくします。 - データ前処理
大量のデータをグループ化して、それぞれのグループの中心点だけを使うことで、データをシンプルにします。
Google CloudにおけるK-means
Google Cloud環境では、以下のサービスでK-meansを利用できます。
- BigQuery ML:SQLだけでK-meansモデルを作成・適用できます。特に大規模データに強いのが特徴です。
- Vertex AI:より柔軟なモデル開発やトレーニング、デプロイが可能です。
K-meansのまとめ
K-meansは「シンプルだけどパワフル」なクラスタリング手法です。使い方や仕組み、注意点(特にkの決め方や前処理)を理解すれば、さまざまな場面で役立つ便利なツールになります。
BigQuery ストリーミング挿入
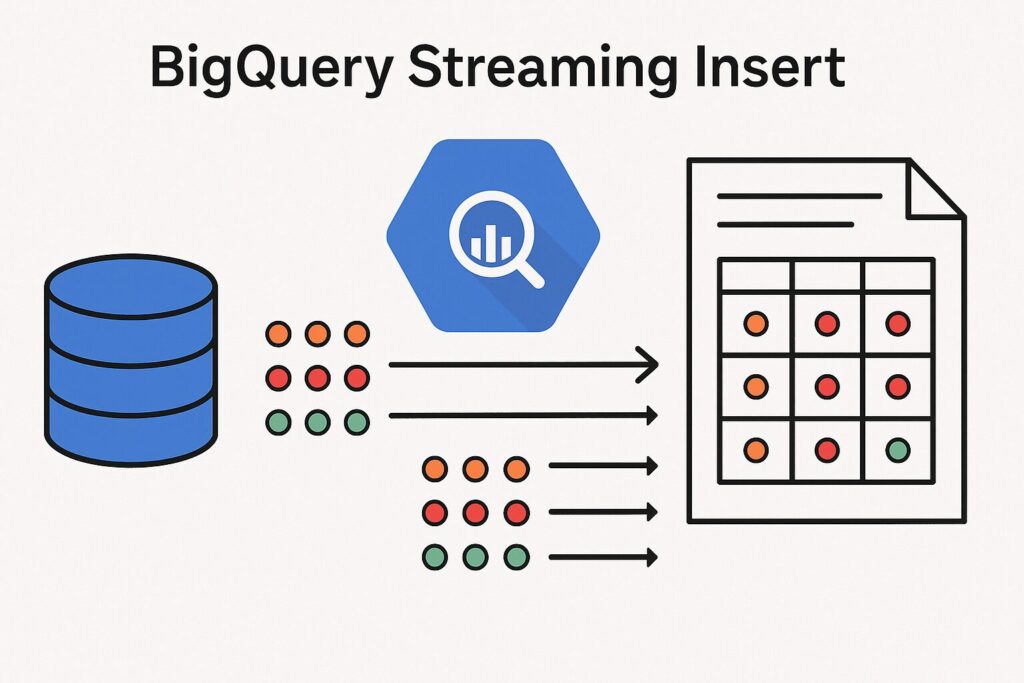
BigQuery ストリーミング挿入とは?
BigQuery ストリーミング挿入は、データをBigQueryテーブルにほぼリアルタイムで、1行ずつまたは小さなバッチで追加するためのメカニズムです。従来のファイルを使ったバッチ読み込みとは対照的なデータ取り込み方法です。
特徴とメリット
- すぐに使えるデータ
ストリーミング挿入されたデータは、通常、数秒以内にクエリで使えるようになります。これにより、リアルタイムに近いダッシュボードや分析が実現できます。 - 小さな単位で送信可能
・データをファイルにまとめる必要はなく、生成された1行ごとのレコードや小さなグループをそのまま送信できます。
・Pub/SubやDataflowといったストリーミング処理パイプラインとの相性も良いです。
ストリーミング挿入とバッチ読み込みの比較
| 特徴 | ストリーミング挿入 | バッチ読み込み |
|---|---|---|
| データ到着 | ほぼリアルタイム (数秒) | 遅延あり (ロードジョブの完了待ち) |
| レイテンシ | 低い | 高い |
| データ単位 | 1行ずつ or 小バッチ | 大量ファイル |
| 主な用途 | リアルタイム分析、ログ、IoTデータ | 大量履歴データ、日次/時間次バッチ処理 |
| 料金 | 挿入データ量に基づく。割高 | ロードは無料(一部例外あり)。ストレージ料金 |
| クォータ | 1秒あたりの行数/バイト数などに制限あり | 1日あたりのジョブ数/テーブル数などに制限あり |
<ポイント>
リアルタイム性が求められる場合はストリーミング挿入、コスト効率や大量データの一括処理が重要な場合はバッチ読み込みを選択します。
考慮事項
- クォータと上限
- ストリーミング挿入には、プロジェクトごと、テーブルごとの秒間挿入バイト数、秒間挿入行数、リクエストサイズなどのクォータがあります。
- これらを考慮した設計が必要です。クォータを超えるとエラーが返されます。
- アプリケーション側でリトライ処理(指数バックオフなど)を実装することが推奨されます。
- 料金
- ストリーミング挿入は、挿入されたデータの量に基づいて課金されます。
- バッチ読み込みと比較してコストが高くなる傾向があります。
- コストとリアルタイム性のトレードオフを理解することが重要です。
- 重複排除 (Best-effort)
- 各行(またはリクエスト内の各行)にユニークな
insertIdを付与することで、BigQueryはベストエフォートでの重複排除を試みます。 - これは、ネットワークエラーなどで同じリクエストが再送された場合に、短時間(通常は数分間)であれば重複して挿入されるのを防ぐための仕組みです。
- 「ベストエフォート」であるため、100%の重複排除を保証するものではありません。厳密な Exactly-Once セマンティクスが必要な場合は、アプリケーションレベルでの追加の仕組み(例:Dataflowでのウィンドウ処理と重複排除)が必要になることがあります。
- 各行(またはリクエスト内の各行)にユニークな
- 可用性
- データはまずストリーミングバッファと呼ばれる一時領域に書き込まれ、すぐにクエリ可能になります。
- その後、バックグラウンドでBigQueryの最適化されたカラム型トレージに非同期で書き込まれます。
- パーティション分割テーブル
- ストリーミング挿入は、時間分割テーブルや整数範囲分割テーブル、取り込み時間パーティション分割テーブルに直接書き込むことができます。データは適切なパーティションにルーティングされます(最初はストリーミングバッファ経由)。
ユースケース
- リアルタイムダッシュボード:ウェブサイトのアクセスログ、アプリケーションのパフォーマンスメトリクス、IoTデバイスからのセンサーデータなどをリアルタイムで可視化。
- 不正検知:金融取引やユーザー行動をリアルタイムで分析し、不正パターンを検出。
- ストリーミングETL/ELT:DataflowやPub/Subから流れてくるデータを変換しつつ、直接BigQueryにロード。
BigQueryストリーミング挿入のまとめ
BigQueryストリーミング挿入は、データをBigQueryに低レイテンシで取り込むための強力な機能です。リアルタイム分析を実現する上で不可欠ですが、バッチ読み込みとの違い(特にコストとクォータ)を理解し、ユースケースに応じて適切に使い分けることが重要です。重複排除のベストエフォート性も念頭に置いて設計しましょう。
Cloud SQLのユースケース
Cloud SQLとは?
まず、Cloud SQLはフルマネージドのリレーショナルデータベースサービスです。MySQL、PostgreSQL、SQL Serverのエンジンをサポートしており、従来型のオンプレミスデータベースと同様の感覚で利用できます。パッチ適用、バックアップ、レプリケーション、フェイルオーバーなどの運用管理をGoogle Cloudが担当してくれます。
Cloud SQLが適している場合
Cloud SQLは、以下のようなケースで特に適しています。
- 既存のリレーショナルデータベース(MySQL、PostgreSQL、SQL Serverなど)をクラウドに移行したい場合
オンプレミスで使っていたデータベースを、なるべく同じ操作感のままクラウドで運用したいときに便利です。アプリケーション側の変更を最小限に抑えてクラウド移行ができます。 - トランザクション処理が重要な業務システムを構築・運用したい場合
銀行やECサイトのように「お金を動かす」「在庫を管理する」など、データの一貫性や信頼性(ACID特性)が求められるシステムに向いています。 - 運用管理の手間を減らしたい場合
パッチの適用、バックアップ、障害時の自動復旧など、日々の面倒な作業をGoogle Cloudが代わりにやってくれるので、インフラ運用の負担を大きく減らせます。 - 標準SQLでデータを扱いたい場合
データの検索や集計などに慣れ親しんだSQLがそのまま使えるので、既存の知識を活かせます。
このように、Cloud SQLは「信頼性の高いリレーショナルデータベースをクラウド上で簡単に使いたい」というニーズにぴったりな選択肢です。
Cloud SQLが最適でない場合(他のサービスの検討)
逆に、以下のような場合は他のサービスが適している可能性が高いです。
- ペタバイト級の大規模データ分析 (OLAP):BigQuery
- グローバル規模での分散、強整合性、水平スケーリングが必要なリレーショナルDB:Cloud Spanner
- スキーマレスなドキュメントデータ、モバイル/Webアプリのバックエンド:Firestore
- IoTデータ、時系列データなど、大量の書き込み/読み込みがあるKey-Value/Wide-columnデータ:Cloud Bigtable
- 非構造化データ(画像、動画、バックアップファイルなど)の保存:Cloud Storage
Cloud SQLのまとめ
Cloud SQLは、既存のリレーショナルデータベースアプリケーションのクラウド移行や、標準SQLとACIDトランザクションを必要とする従来のOLTPアプリケーションをGoogle Cloud上で構築・運用する際の堅実な選択肢です。使い慣れたインターフェースとフルマネージドの利便性を両立しており、多くの一般的なWebアプリケーションや業務システムに適しています。
Dataflowパイプラインの停止方法
Dataflowパイプラインは、Dataflowを用いて大規模なデータをリアルタイムまたはバッチで処理するための処理フローです。Apache Beam SDKを使用してパイプラインを定義し、分散処理によってスケーラブルで効率的なデータ変換・集計を実現します。ストリーミング処理にも対応しており、Pub/SubやBigQueryなど他のGoogle Cloudサービスと連携可能です。
Dataflowパイプラインを停止するには、主に2つの方法があります。「キャンセル (Cancel)」と「ドレイン (Drain)」で、それぞれ動作と影響が異なります。
1. キャンセル(Cancel)
動作
Dataflowサービスに対し、パイプラインの即時停止を試みるよう指示します。実行中のデータ処理や新しいデータの取り込みが直ちに中断されます。
影響
- 処理中のデータは失われる可能性があります。
- パイプラインの状態(Stateful DoFn内の状態など)は保持されません。
- Compute Engine VMなどのリソースは速やかにシャットダウンされます。
用途
パイプラインを緊急に停止したい場合、データ損失が許容できる場合、コストをすぐに削減したい場合など。
2. ドレイン (Drain)
動作
パイプラインに対し、新しいデータの入力を停止し、現在処理中およびバッファにある既存のデータをすべて処理し終えるまで待つよう指示します。ウォーターマークがすべてのウィンドウの終端を通過するまで処理が続行されます。
影響
- 処理中のデータは最後まで処理されるため、データ損失を最小限に抑えられます。
- パイプラインの状態は、処理が完了するまで保持されます。
- すべてのデータが処理されるまでリソースが稼働し続けるため、パイプラインの停止(完了)までに時間がかかる可能性があり、その間コストが発生します。
用途
処理中のデータを失わずにパイプラインを正常に終了させたい場合、パイプラインのコードを更新する準備(ドレイン後に新しいバージョンのジョブを開始する)など。
選択のポイント
- データ損失を避けたい場合や、処理をきれいに完了させたい場合は「ドレイン」を選択します。
- パイプラインをすぐに停止する必要があり、データ損失が許容できる場合は「キャンセル」を選択します。
実行方法
これらの停止操作は、Google Cloud Console、gcloud コマンド、またはDataflow APIを通じて実行できます。
Dataflowパイプラインの停止方法のまとめ
Dataflowパイプラインの停止方法には、「キャンセル」と「ドレイン」の2つがあります。キャンセルは即時停止を行い、データ損失の可能性がありますがコスト削減には有効です。一方、ドレインは処理中のデータをすべて完了させてから停止するため、データ損失を抑えられます。用途に応じて適切な方法を選ぶことが重要です。操作はCloud Consoleやgcloud コマンドなどで実行できます。
Dataflowパイプライン更新
Dataflowのパイプライン更新機能を使うと、実行中のジョブを停止せずに新しいコードに置き換えることができますが、ウィンドウ処理ロジックの変更には大きな制約があります。
基本的な制約
- 実行中のパイプラインのウィンドウ処理戦略(例:固定時間ウィンドウからセッションウィンドウへの変更、ウィンドウ期間の変更など)を、更新機能を使って直接変更することはできません。
- このような変更を伴う更新を実行しようとすると、通常、更新ジョブは失敗します。
理由
- ウィンドウ処理は、GroupByKeyやCombineといったステートフルな(状態を持つ)処理の基盤となります。データは特定のウィンドウごとにグループ化され、状態もそのウィンドウに関連付けられています。
- ウィンドウ処理戦略を変更すると、データのグループ化方法や状態の管理方法が根本的に変わってしまいます。Dataflowは、古いウィンドウ戦略に基づいた状態を、新しい互換性のないウィンドウ戦略へ自動的にマッピングしたり移行したりすることができません。
推奨される対処法
パイプラインのウィンドウ処理ロジックを変更したい場合の推奨される方法は、「ドレインして新しいジョブを開始する」ことです。
- 現在のパイプラインをドレイン (Drain) します。これにより、既存のデータは古いウィンドウ処理ロジックで正常に処理されます。
- ドレインが完了するのを待ちます。
- 変更後の新しいウィンドウ処理ロジックを含むパイプラインを、新しいジョブとして起動 します。
結論
パイプラインの更新機能は便利ですが、ウィンドウ処理のようなパイプラインの基本的な構造に関わる変更には適していません。ウィンドウ処理を変更する場合は、既存のジョブをドレインし、新しいジョブとして再デプロイするのが標準的で安全な方法です。
Dataflowパイプライン更新のまとめ
Dataflowのパイプライン更新機能では、実行中のジョブを停止せずにコードを更新できますが、ウィンドウ処理ロジックの変更には対応していません。ウィンドウ戦略を変更すると状態管理が破綻するため、更新ジョブは失敗します。そのため、ウィンドウ処理を変更する場合は、一度ドレインしてから新しいジョブを起動する方法が推奨されます。
まとめ
今回は、下記5点について説明しました。
- K-means
- BigQuery ストリーミング挿入
- Cloud SQLのユースケース
- Dataflowパイプラインの停止方法
- Dataflowパイプライン更新
今回のブログでは、K-meansによるデータクラスタリングから始まり、BigQueryのリアルタイム分析、Cloud SQLの活用、そしてDataflowの停止・更新といった実運用の要点を網羅しています。各技術の特性や注意点を理解することで、より効率的かつ信頼性の高いクラウドアーキテクチャを設計・運用できるようになります。
これからも、Macのシステムエンジニアとして、日々、習得した知識や経験を発信していきますので、是非、ブックマーク登録してくれると嬉しいです!
それでは、次回のブログで!

