
今回も、Professional Cloud Data Engineer認定取得するために、私が勉強した内容をアウトプットしていきます。
今回は、BigQuery のタイムトラベル、BigQueryの管理リソースグラフ、BigQueryのオンデマンドとエディションの選択基準について説明します!
ぜひ、最後までご覧いただけると嬉しいです!
BigQuery のタイムトラベル
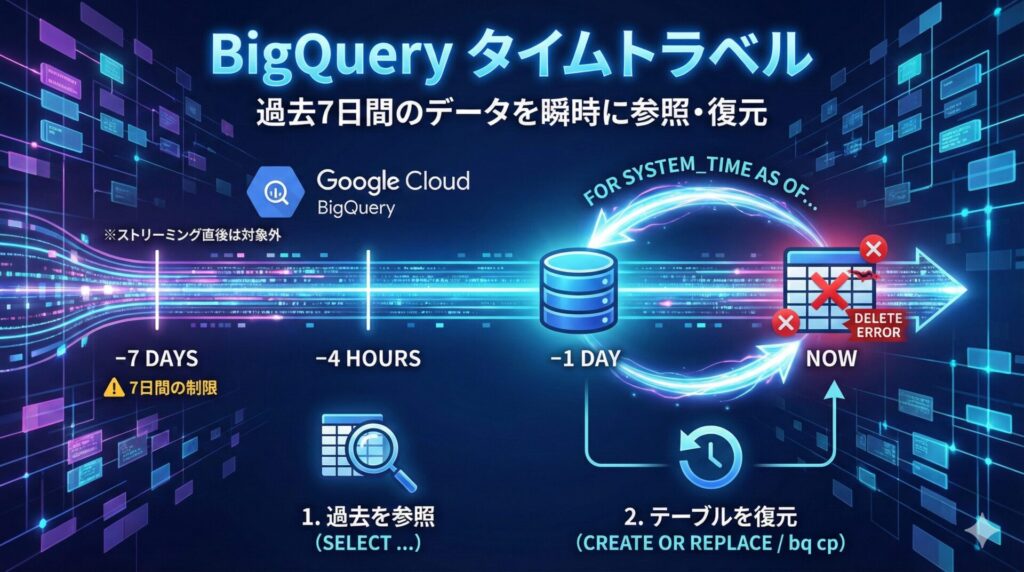
タイムトラベルは、BigQuery が自動的にテーブルの履歴データを保持してくれる機能です。これにより、ユーザーは過去7日間の任意の時点にさかのぼり、そのスナップショットのデータをクエリ(参照)できます。
- 主な目的:誤った DML(UPDATE, DELETE, MERGE)操作や、テーブルの DROP からのリカバリ。
- 保持期間:デフォルトで7日間。
- この期間は、データセット単位で 2 日から 7 日の間で設定変更も可能です(7 日より長くはできません)。
- 対象:BigQuery のマネージド ストレージに保存されているデータ。
タイムトラベルの使い方:FOR SYSTEM_TIME AS OF
タイムトラベルの利用は非常に簡単で、特別な設定は不要です。使い方は、SELECT 文の FROM 句の後ろに FOR SYSTEM_TIME AS OF を追加するだけです。
1. 過去のデータを「参照」する
例えば、3時間前に誤った DELETE を実行してしまった場合、4時間前の状態を参照できます。
SELECT
*
FROM
`my_project.my_dataset.my_table`
FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 4 HOUR)
WHERE
-- 4時間前には存在していたはずのデータを指定
user_id = 1232. テーブルを「復元」する
参照するだけでなく、過去のデータを使ってテーブルを丸ごと復元(書き戻し)することも可能です。
ケース1:(もしテーブルごと削除した場合)まずテーブルを復元bq cp コマンドを使い、特定の時間のスナップショットを新しいテーブルとしてコピーします。@ の後にミリ秒単位の Unix タイムスタンプを指定します。
# 2時間前のスナップショット(@1699261200000)を
# `my_table_restored` という名前で復元する
bq cp my_project:my_dataset.my_table@1699261200000 \
my_project:my_dataset.my_table_restoredケース2:(テーブルは存在し、データだけ間違えた場合)データを上書き復元
まず、過去のデータを別の一時テーブルに取得し、その後、元のテーブルをその一時テーブルのデータで置き換えるか、一時テーブルから元のテーブルへデータを挿入します。
BEGIN
-- Step 1: 1日前のテーブルデータを一時テーブルに保存
CREATE TEMP TABLE temp_restore_data AS
SELECT
*
FROM
`my_project.my_dataset.my_table`
FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 DAY);
-- Step 2: 元のテーブルを一時テーブルの内容で完全に置き換える
CREATE OR REPLACE TABLE `my_project.my_dataset.my_table` AS
SELECT
*
FROM
temp_restore_data;
-- ※TEMP TABLEはセッション終了時に自動削除されます
END;知っておくべき制限事項
タイムトラベルは強力ですが、万能ではありません。以下の点に注意してください。
- 7日間の制限:これは短期的な安全策です。7日以上前のデータは復元できません。長期的なバックアップが必要な場合は、別途「テーブル スナップショット」を作成する必要があります。
- ストリーミング バッファは対象外:
Storage Write APIやレガシーなtabledata.insertAllAPI を使ってストリーミング挿入されたデータは、まず「ストリーミング バッファ」に入ります。タイムトラベルは、データがバッファから BigQuery のマネージド ストレージに書き込まれた後(通常、数分~数十分後)に初めて対象となります。挿入直後のデータは巻き戻せません。 - 明示的に削除されたデータセット:テーブル単位ではなく、データセットごと削除した場合、その中のテーブルはタイムトラベルで復元できません。
BigQuery のタイムトラベルのまとめ
BigQuery のタイムトラベルは、過去7日間の任意時点のテーブル状態を簡単に参照・復元できる強力な安全機能です。
誤った DML 操作やテーブル削除からのリカバリに役立ち、SQL に FOR SYSTEM_TIME AS OF を指定するだけで利用できます。また、過去状態を新しいテーブルとしてコピーしたり、現在のテーブルを過去データで上書きすることも可能です。ただし、保持期間は最大7日間で、ストリーミングバッファ内のデータや削除されたデータセットは対象外となります。
長期保存が必要な場合は、テーブルスナップショットなどと併用することが重要です。
BigQueryの管理リソースグラフ
BigQuery を組織全体で使っていると、管理者としては「一体、誰がどれだけスロットを使ってるんだ?」「最近クエリが遅い気がするけど、リソースが足りてない?」といった疑問が頭をよぎるものです。
そんな疑問に答えるため、Google Cloud コンソールには「管理リソースグラフ」という強力なダッシュボードが用意されています。
これは、個々のユーザーが見るクエリ履歴とは異なり、管理者(bigquery.resourceAdmin ロールなどを持つユーザー)が組織全体またはプロジェクト単位の BigQuery の健全性を把握するために特化したモニタリング ツールです。
管理リソースグラフで「見える」こと
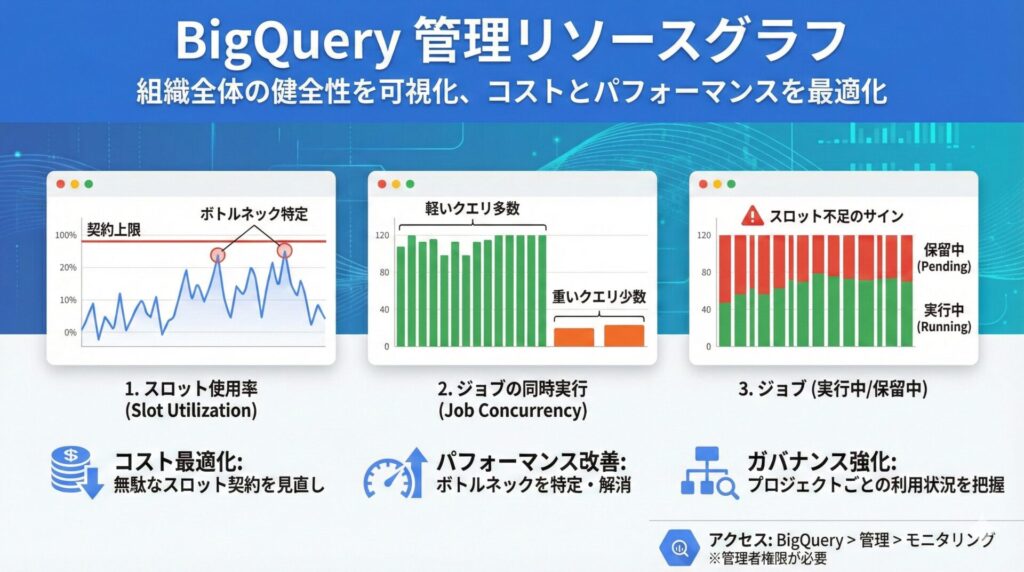
このダッシュボードのすごいところは、組織全体の BigQuery の動きを、集約された分かりやすいグラフで示してくれる点です。主なグラフは以下の3つです。
1. スロット使用率 (Slot Utilization)
これが最も重要なグラフです。
- 組織(またはプロジェクト)で購入・契約しているスロットに対して、実際にどれだけのスロットが消費されているかを時系列で表示します。
- 「週末の夜間にバッチ処理が集中しているな」「平日の日中は意外と余裕がある」といった、リソース消費のピークと谷を正確に把握できます。
- スロットが契約上限に張り付いている時間帯があれば、それがパフォーマンス低下(ジョブの待機)の原因である可能性が一目瞭然です。
2. ジョブの同時実行 (Job Concurrency)
文字通り、同時に実行されているジョブの数を示します。
- スロット使用率が低いのに同時実行ジョブ数が多い場合、それは「軽い(スロット消費が少ない)クエリ」がたくさん実行されていることを意味します。
- 逆に、同時実行ジョブ数は少ないのにスロット使用率が天井に張り付いている場合、「非常に重い(スロットを大量に消費する)クエリ」が少数実行されていることがわかります。
3. ジョブ (実行中/保留中)
これは、ジョブの状態の内訳を示します。
- 実行中 (Running):実際にスロットを割り当てられ、処理が動いているジョブの数。
- 保留中 (Pending):実行をリクエストされたものの、スロットの空きがないため「待たされて」いるジョブの数。
「保留中」のジョブが常時発生している場合、それはスロットが不足している明確なサインです。
なぜ管理リソースグラフが重要なのか?
このダッシュボードは、BigQuery 環境の「健康診断」そのものです。
- コストの最適化:「スロット使用率が常に低いままなら、契約スロット数を減らしてコスト削減できるかも?」という判断材料になります。
- パフォーマンスのボトルネック特定:「『保留中』のジョブが特定の時間帯に急増している。このバッチ処理の時間をずらそう」といった対策が打てます。
- 組織的なガバナンス:組織全体でリソースがどう使われているかを把握することで、スロットを大量に消費している特定のプロジェクトを特定し、クエリの最適化を促すといったアクションにつながります。
アクセス方法
このグラフは、Google Cloud コンソールの [BigQuery] セクションにある [管理] > [モニタリング] ページからアクセスできます。
(※必要な IAM 権限、主に bigquery.resourceAdmin ロールに含まれる bigquery.jobs.listAll や monitoring.timeSeries.list などが必要です。)
BigQueryの管理リソースグラフのまとめ
BigQuery の管理リソースグラフは、組織全体のクエリ動作やリソース消費状況を俯瞰できる管理者向けダッシュボードです。
スロット使用率・ジョブ同時実行数・実行中/保留中ジョブといった重要指標を可視化し、パフォーマンス低下やリソース不足の原因を特定できます。これにより、スロット契約数の最適化やバッチ処理の時間調整など、効果的なコスト管理とパフォーマンス改善が可能になります。また、組織全体のリソース使用状況を把握することで、プロジェクト単位の最適化やガバナンス強化にも役立ちます。
アクセスには管理者権限が必要ですが、BigQuery 環境の健康状態を把握する上で欠かせないツールです。
BigQueryのオンデマンドとエディションの選択基準

BigQueryの料金プラン選択は、データエンジニアリングにおける最も重要な決定の1つです。 選択の基準は、大きく分けて2段階あります。
1. 「コストの予測性」(オンデマンド vs 容量)
2. 「必要な機能(特にセキュリティ)」(どのエディションか)
2つの主な料金モデル
まず、BigQueryの分析(クエリ)料金には、根本的に2つの支払い方法があります。
1. オンデマンド料金 (On-Demand)
クエリがスキャンしたデータ量 (TiB) に応じてお金を払う、シンプルな従量課金モデルです。
2. 容量料金 (Editions)
「スロット」と呼ばれる処理能力(コンピューティング)を、時間単位(または月/年コミット)で購入する、定額制(または予測可能)なモデルです。この容量モデルが、Standard / Enterprise / Enterprise Plus の3つのエディションに分かれています。
最初の判断基準: オンデマンド vs 容量(エディション)
| 比較項目 | オンデマンド (On-Demand) | 容量(エディション)(Capacity) |
| 課金対象 | スキャンしたデータ量(TiB) | 処理能力(スロット)の時間 |
| コストの予測性 | 低い(予測しづらい) | 高い(事前に計画しやすい) |
| パフォーマンス | 共有スロット:混雑時に遅くなる可能性あり | 専用・予約済み:安定した性能 |
| 最適なユースケース | ・開発・検証 ・アドホック分析 ・クエリ頻度が低い ・コスト予測が不要 | ・本番ワークロード ・BI ダッシュボード ・定期バッチ / ETL ・コストを固定したい・予測したい |
判断のヒント
- 「コストが予測不能でもいいから、使った分だけ払いたい」 -> オンデマンド
- 「スキャン量を気にせず、BIダッシュボードをリロードしたい」 -> 容量 (エディション)
- 「毎月の分析予算を固定化したい」 -> 容量 (エディション)
- 「クエリが失敗したアナリストから『スキャン量を見直せ』と怒られたくない」 -> 容量 (エディション)
一般的に、組織の利用が本格化し、オンデマンドの料金が高額かつ不安定になってきたら、「容量(エディション)」モデルに切り替えるのが王道のパターンです。
次の判断基準:どのエディション(Standard / Enterprise / Enterprise Plus)を選ぶか?
次に「どのエディションを選ぶか」を決めます。 重要なのは、この3つの違いは「パフォーマンス(速度)」ではなく、「機能(主にセキュリティとガバナンス)」であるという点です。
1. Standard Edition
- 特徴:基本的な容量(スロット)のみ。
- 機能:SQL、BigQuery ML、BI Engine など、BigQueryの基本機能はすべて使えます。
- 欠点:高度なセキュリティ機能が欠けています。CMEK (顧客管理の暗号鍵) や VPC Service Controls などが使えません。
- 判断基準
- 「とにかくコストを固定したい。機密データは扱っておらず、厳密なセキュリティは不要」という場合に選びます。
2. Enterprise Edition
- 特徴:ほとんどの企業にとっての「標準」であり「最適解」です。
- 機能:Standard の全機能に加え、データエンジニアが本番環境で必要とするほぼすべてのセキュリティ・ガバナンス機能が揃います。
- CMEK (顧客管理の暗号鍵)
- VPC Service Controls (ネットワーク境界制御)
- 列レベルのセキュリティ ◦ データマスキング
- BigQuery Omni (マルチクラウド分析)
これらに1つでも当てはまる(あるいは、よくわからないが安全にしておきたい)場合は、Enterprise を選ぶべきです。
3. Enterprise Plus Edition
- 特徴:「最高レベルのコンプライアンスと信頼性」を求める組織向け。
- 機能:Enterprise の全機能に加え、以下のような規制対応機能が追加されます。
- Assured Workloads (データ所在地や担当者を厳密に制限。例: FedRAMP)
- 強化されたディザスタリカバリ (DR)
- より低いスロットコミットメント(100単位)
- 判断基準
- 「政府機関」「国際的な金融」「高度な医療」など、極めて厳格なデータ主権やコンプライアンス規制(例:「データはEUから一歩も出してはいけない」)に対応する必要がある場合にのみ選択します。
結論
- 質問A: コストは「使った分だけ(予測不能)」と「定額(予測可能)」のどちらが良いか? ◦
- 使った分だけ -> オンデマンド (ここで終了)
- 定額 -> 容量(エディション) (質問2へ)
- 質問B: CMEK や VPC-SC といった高度なセキュリティ・ガバナンス機能が必要か?
- いいえ -> Standard Edition
- はい -> Enterprise Edition (質問3へ)
- 質問C: Assured Workloads のような、政府レベルの厳格なコンプライアンス要件があるか?
- いいえ -> Enterprise Edition (ここで終了)
- はい -> Enterprise Plus Edition
BigQueryのオンデマンドとエディションの選択基準のまとめ
BigQuery の料金選択は、「コストの予測性」と「必要な機能(特にセキュリティ)」の2軸で判断することが重要です。
クエリ量に応じて支払うオンデマンドは開発や軽めの利用に適し、コストを固定したい場合は容量(エディション)モデルが最適です。エディション選びは性能ではなく機能差がポイントで、一般企業ならセキュリティ機能が充実した Enterprise Edition が最も現実的な選択肢です。CMEK や VPC-SC が不要なら Standard、政府・金融レベルの厳格な規制がある場合のみ Enterprise Plus を選ぶべきです。
最終的には、利用状況と求められるセキュリティ基準に応じて段階的に判断するのが最も失敗のないアプローチです。
まとめ
今回は、下記3点について説明しました。
- BigQuery のタイムトラベル
- BigQueryの管理リソースグラフ
- BigQueryのオンデマンドとエディションの選択基準
BigQuery を効果的に運用するには、データ保護、リソース管理、料金モデルの3つを総合的に理解することが重要です。
タイムトラベル機能により、誤操作や削除からの迅速な復元が可能となり、データの安全性が大幅に向上します。管理リソースグラフは、組織全体のリソース消費を可視化し、パフォーマンス改善やコスト最適化の判断を強力に支援します。さらに、料金モデルの選択は利用形態と求めるセキュリティに応じて決める必要があり、オンデマンドとエディションを適切に使い分けることが鍵となります。
これら3つを組み合わせて活用することで、BigQuery をより安全・効率的・戦略的に運用できるようになります。
これからも、Macのシステムエンジニアとして、日々、習得した知識や経験を発信していきますので、是非、ブックマーク登録してくれると嬉しいです!
それでは、次回のブログで!

