
Professional Cloud Developer 認定試験では、「可用性」「運用設計」「リアルタイム処理」といった複数の観点を横断した設計力が問われます。
本記事では、GKEの可用性を守るPod Disruption Budget、先手を打つ運用を実現するアップグレード通知、そして高性能なリアルタイムデータ処理基盤の設計手法を解説します。いずれも単なる機能理解ではなく、実務での意思決定に直結する重要なテーマです。
クラウドネイティブな設計力を高めるためのポイントを体系的に整理します。
是非、最後までご覧いただけると嬉しいです。
Pod Disruption Budget(PDB)の仕組みと実践ガイド

GKE(Google Kubernetes Engine)のようなマネージドサービスを利用する最大の利点は、ノードのパッチ適用やアップグレードが自動化されることです。しかし、この「自動メンテナンス」は、裏を返せば「Googleが都合の良いタイミングでPodを終了させる可能性がある」ことを意味します。
メンテナンス中もサービスを止めたくない運用者にとって、最強の味方となるのがPod Disruption Budget(PDB)です。本記事では、PDBの仕組みから設定のコツまで、GKE運用の現場で役立つ知識を凝縮して解説します。
1. Pod Disruption Budget (PDB) とは?
PDBを一言で言えば、「メンテナンスなどでPodが削除される際、最低限維持してほしいPodの数をKubernetesに約束させるルール」です。
GKEがノードをアップグレードする際、そのノード上のPodは一旦削除され、別のノードへ移動(再スケジュール)されます。もし、同じアプリケーションのPodがすべて一つのノードに乗っていたり、同時にすべてのノードが更新されたりすると、一時的に「全滅」してサービスダウンが発生します。PDBはこれを防ぐための「防波堤」となります。
2. 「自発的」と「非自発的」:PDBが守れるもの・守れないもの
PDBを理解する上で最も重要なのが、「自発的な中断(Voluntary Disruptions)」という概念です。
| 中断の種類 | 具体例 | PDBの適用 |
|---|---|---|
| 自発的 (Voluntary) | GKEの自動アップグレード、kubectl drain、デプロイメントのローリングアップデート | 適用される(守れる) |
| 非自発的 (Involuntary) | ノードのハードウェア故障、カーネルパニック、クラウドのゾーン障害 | 適用されない(守れない) |
💡 ポイント
PDBが尊重されるのは、Eviction APIを経由したPodの削除操作(kubectl drain や GKEの自動アップグレードなど)に限られます。HPAによるスケールダウンはEviction APIではなくDeleteリクエストで実行されるため、PDBの保護対象外となります。また、物理的な故障やリソース不足によるkubeletの強制退去(node pressure eviction)からもPodを守ることはできません。
3. PDBの具体的な設定方法
PDBには、2通りの指定方法があります。アプリケーションの特性に合わせて使い分けましょう。
① minAvailable(最小可用数)
「常に最低◯個は動いていてほしい」という指定です。
例:レプリカ数が10個のとき、minAvailable: 8 に設定すると、メンテナンス等で同時に削除されるのは2個までになります。
② maxUnavailable(最大不可用数)
「同時に落としていいのは最大◯個まで」という指定です。
例:maxUnavailable: 1 に設定すると、1つのPodが新しいノードで起動してReady状態になるまで、次のPodは削除されません。ローリングアップデートのような動きを強制したい場合に有効です。
どちらの形式でも、数値(例:2)だけでなくパーセンテージ(例:25%)での指定が可能です。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-app-pdb
spec:
minAvailable: 2 # または maxUnavailable: 1
selector:
matchLabels:
app: my-app4. GKEにおけるベストプラクティス
GKEの自動アップグレードやノード自動プロビジョニング(NAP)を最大限に活かすための、PDB運用の鉄則を紹介します。
ステップ1:レプリカ数は「2以上」が必須
当然ですが、Podが1つしかない場合、minAvailable: 1 を設定すると、KubernetesはそのPodを永遠に削除できなくなります。これはノードのアップグレードが止まってしまう原因(後述)になります。可用性を高めるなら、最低2つ以上のレプリカを構成しましょう。
ステップ2:Graceful Termination(優雅な終了)との併用
PDBでPodの生存を確保しても、Podの終了処理が雑であればリクエストがこぼれます。
terminationGracePeriodSecondsを適切に設定する。preStopフックで、ロードバランサーから切り離されるまで数秒待機する処理を入れる。
ステップ3:PDBの「デッドロック」に注意
あまりに厳しいPDB(例:2個中2個必須など)を設定すると、ノードのアップグレードがいつまでも完了せず、GKEがエラーを吐き続けることになります。
解決策: メンテナンス時のみレプリカ数を一時的に増やすか、PDBの制限を少し緩めに設計しましょう。
Pod Disruption Budget(PDB)の仕組みと実践ガイドのまとめ
Pod Disruption Budget(PDB)は、GKEの自動メンテナンスにおいてサービス停止を防ぐための重要な仕組みです。自発的な中断に対して最小限の可用性を保証できる一方で、障害などの非自発的な中断には対応できない点を正しく理解する必要があります。
minAvailable や maxUnavailable を適切に設定し、アプリケーション特性に合わせた設計が求められます。また、レプリカ数の確保や Graceful Termination との組み合わせにより、より安定した運用が実現できます。過度に厳しい設定はアップグレード停滞を招くため注意が必要です。
PDBを正しく活用することで、可用性と運用性を両立した堅牢なシステムを構築できます。
GKEのアップグレード通知をリアルタイムで受け取る方法
GKE(Google Kubernetes Engine)を運用する上で、最も避けたいのは「知らないうちにアップグレードが始まり、サービスに影響が出る」あるいは「重要なセキュリティパッチの存在に気づかない」という事態です。
Google Cloudには、クラスターの状態やアップグレード予定をリアルタイムにキャッチするための強力な通知エコシステムが備わっています。本記事では、公式ドキュメントに基づき、運用担当者が「攻め」の運用を行うための通知設定ガイドを解説します。
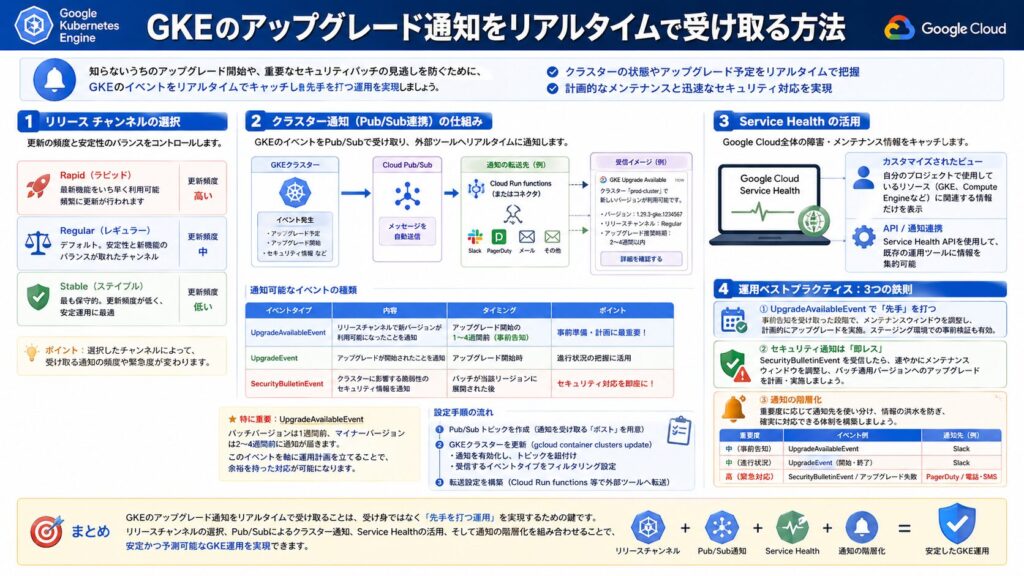
1. 全ての基盤:リリース チャンネルの選択
通知を設定する前に、そもそも「いつ、どのような頻度でアップデートが来るのか」を制御する必要があります。これがリリース チャンネルの概念です。
- Rapid(ラピッド): 最新機能をいち早く利用。頻繁な更新。
- Regular(レギュラー): デフォルト。安定性と新機能のバランス。
- Stable(ステイブル): 最も保守的。更新頻度が低い。
どのチャンネルを選択しているかによって、受け取る通知の頻度と緊急度が変わります。
2. 核心機能:クラスター通知 (Pub/Sub連携)
GKEのアップグレード予定やセキュリティ速報を、SlackやPagerDutyといった外部ツールに直接飛ばすための最も確実な方法が、Pub/Subを利用したクラスター通知です。
仕組み
GKEクラスターで「イベント」が発生すると、指定した Cloud Pub/Sub トピックにメッセージが自動送信されます。これを Cloud Run Functions やサードパーティ製のコネクタで購読することで、自由な形式で通知を受け取れます。
通知可能なイベントの種類
GKEのクラスター通知では、以下の3種類の主要イベントが利用できます。それぞれの役割を正しく理解することが「攻めの運用」の鍵です。
| イベントタイプ | 内容 | タイミング |
|---|---|---|
UpgradeAvailableEvent | リリースチャンネルで新バージョンが利用可能になったことを通知 | アップグレード開始の1〜4週間前(事前告知) |
UpgradeEvent | アップグレードが開始されたことを通知 | アップグレード開始時 |
SecurityBulletinEvent | クラスターに影響する脆弱性のセキュリティ情報を通知 | パッチが当該リージョンに展開された後 |
💡 特に重要なのは UpgradeAvailableEvent
パッチバージョンは1週間前、マイナーバージョンは2〜4週間前に通知が届くため、メンテナンスウィンドウの調整など、事前準備のための時間的余裕が得られます。「アップグレードが始まってから気づく」のではなく、このイベントを軸に運用計画を立てるのが理想的です。
設定手順
- Pub/Sub トピックを作成:通知を受け取るための「ポスト」を用意します。
- GKEクラスターを更新:
gcloud container clusters updateコマンドで、通知を有効化し、先ほど作成したトピックを紐付けます。受信するイベントタイプをフィルタリングすることも可能です。 - 転送設定:Pub/SubからSlack等へ転送する仕組み(Cloud Run functionsなど)を構築します。
3. 広域情報のキャッチ:Service Health
GKE自体の設定ではなく、Google Cloudのインフラ全体に影響する障害やメンテナンス情報を知るには、Google Cloud Service Health を活用します。
- カスタマイズされたビュー:自分のプロジェクトで使用しているリソース(GKE、Compute Engineなど)に関連する障害情報だけをフィルタリングして確認できます。
- API/通知連携:Service Health APIを使用することで、Google Cloudコンソールを開かずとも、既存の運用ツールに情報を集約できます。
4. 運用ベストプラクティス:3つの鉄則
通知を受け取れるようになったら、以下の運用ルールを設けるのが「プロ」のやり方です。
① UpgradeAvailableEvent で「先手」を打つ
アップグレードが始まってから慌てるのではなく、UpgradeAvailableEvent を受け取った段階でメンテナンスウィンドウを調整し、自分たちのタイミングで計画的にアップグレードを実施しましょう。余裕があれば、ステージング環境で先行して動作確認することも可能です。
② セキュリティ通知は「即レス」
SecurityBulletinEvent は、脆弱性への対応を促すものです。これを受け取ったら、速やかにメンテナンス ウィンドウを調整し、パッチを適用したバージョンへのアップグレードを計画しましょう。
③ 通知の階層化
「全ての通知をSlackに流す」と、情報の洪水に埋もれてしまいます。
- Slack:
UpgradeAvailableEvent(事前告知)、通常のアップグレード開始・終了 - PagerDuty/モバイルアプリ:
SecurityBulletinEvent(重大なセキュリティパッチ)、アップグレードの失敗
といった具合に、重要度に応じた通知先を使い分けるのがコツです。
GKEのアップグレード通知をリアルタイムで受け取る方法のまとめ
GKEのアップグレード通知は、受け身ではなく「先手を打つ運用」を実現するための重要な仕組みです。リリースチャンネルで更新頻度をコントロールし、Pub/Subによるクラスター通知でイベントをリアルタイムに把握することが基本となります。
特にUpgradeAvailableEventを活用することで、計画的なメンテナンスや事前検証が可能になります。さらに、Service Healthを併用することで、広域的な障害情報も見逃しません。通知は重要度に応じて適切に振り分けることが運用効率の鍵です。
これらを組み合わせることで、安定かつ予測可能なGKE運用を実現できます。
リアルタイムデータ処理の設計手法
1分1秒、いや1ミリ秒が勝負を分ける株価データの世界。このような「超低レイテンシ」と「膨大なスループット」の両立が求められるシステムを、自前のサーバーで構築・維持するのは至難の業です。
Google Cloudには、こうしたリアルタイム・データパイプラインを支える強力なサービス群が存在します。本記事では、Pub/Sub・Dataflow・Bigtable・BigQueryを組み合わせた、モダンなリアルタイム・アプリケーションの設計手法を解説します。
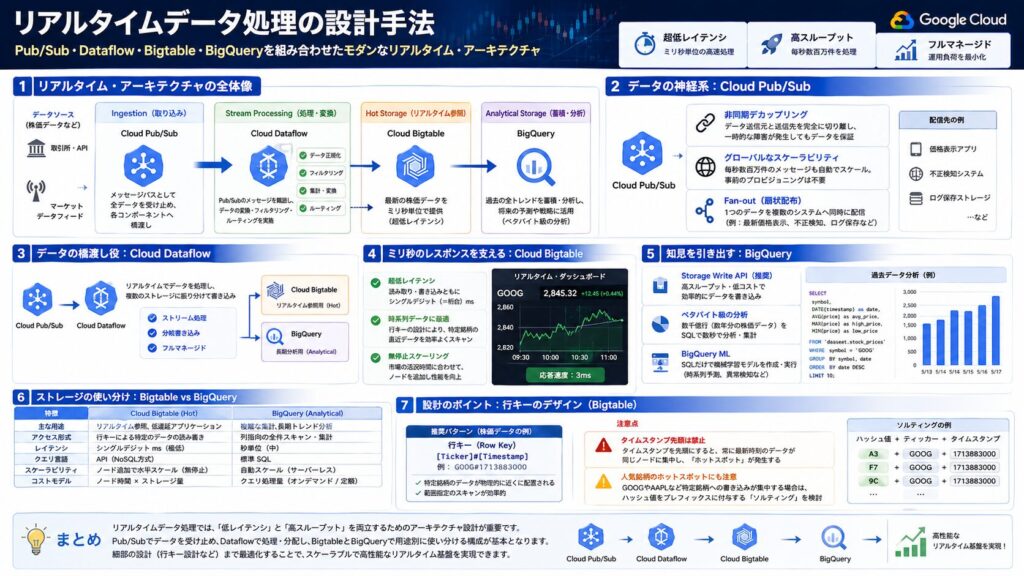
1. リアルタイム・アーキテクチャの全体像
株価データのようなイベント駆動型のシステムでは、データの「鮮度」を保ったまま、いかに効率よく分配・保存・分析するかが鍵となります。推奨される標準的なアーキテクチャは以下の通りです。
- Ingestion(取り込み): Cloud Pub/Subが全データを受け止め、メッセージバスとして各コンポーネントへ橋渡しします。
- Stream Processing(処理・変換): Cloud DataflowがPub/Subのメッセージを購読し、データの変換・フィルタリング・ルーティングを行います。Pub/SubはBigtableやBigQueryに直接書き込めないため、この層が不可欠です。
- Hot Storage(リアルタイム参照): Cloud BigtableがDataflow経由で書き込まれた最新の株価をミリ秒単位で提供します。
- Analytical Storage(蓄積・分析): BigQueryがDataflow経由で蓄積された過去の全トレンドを分析し、将来の予測に活用します。
2. データの神経系:Cloud Pub/Sub
システム全体の「メッセージバス」として機能するのが Cloud Pub/Sub です。
- 非同期デカップリング:データ送信元(取引所など)と送信先(データベースやアプリ)を完全に切り離します。これにより、一方が一時的にダウンしてもデータが失われることはありません。
- グローバルなスケーラビリティ:毎秒数百万件のメッセージが届いても、事前のプロビジョニングなしで自動スケーリングします。
- Fan-out(扇状配布):1つの株価データを、「最新価格表示用」「不正検知用」「ログ保存用」など、複数の異なるシステムへ同時に転送できます。
3. データの橋渡し役:Cloud Dataflow
Pub/SubとBigtable・BigQueryをつなぐ「処理層」として必須なのが Cloud Dataflow です。
- ストリーム処理:Pub/Subのメッセージをリアルタイムで購読し、データの正規化・フィルタリング・変換を行います。
- 分岐書き込み:処理済みデータを Bigtable(リアルタイム参照用)と BigQuery(長期分析用)に同時に書き込みます。
- フルマネージド:Apache Beamベースの処理エンジンを、サーバー管理不要で実行できます。
4. ミリ秒のレスポンスを支える:Cloud Bigtable
リアルタイム・ダッシュボードや自動取引システムが「今の価格」を必要とする時、呼び出すべきは Cloud Bigtable です。
- 超低レイテンシ:読み取り・書き込みともにシングルデジット(一桁台)のミリ秒レイテンシを実現します。これは標準的なリレーショナルデータベース(RDB)では到達困難な領域です。
- 時系列データへの最適化:Bigtableは広大な「キー・バリュー」ストアであり、行キーの設計(後述)によって特定の銘柄の直近の推移を効率よくスキャンできます。
- 無停止スケーリング:市場の取引が活発になる時間帯に合わせて、稼働させたままノード数を増やし、処理能力を向上させることが可能です。
5. 知見を引き出す:BigQuery
リアルタイムな動きを追うだけでなく、過去のパターンから戦略を練るために欠かせないのが BigQuery です。
- Storage Write API:Dataflowからデータを高スループット・低コストでBigQueryに書き込む際は、レガシーな「ストリーミング・インサートAPI」ではなく、Googleが現在推奨する BigQuery Storage Write API を使用します。
- ペタバイト級の分析:数年分の株価データ(数千億行)に対しても、SQLを使って数秒で集計や相関分析を実行できます。
- BigQuery ML:蓄積したデータに対し、SQLだけで機械学習モデル(時系列予測など)を作成・実行できるため、エンジニアが予測アルゴリズムを迅速にテストできます。
6. ストレージの使い分け:Bigtable vs BigQuery
「どちらに保存すべきか?」という問いへの答えは、「用途によって両方使う」です。
| 特徴 | Cloud Bigtable (Hot) | BigQuery (Analytical) |
|---|---|---|
| 主な用途 | リアルタイム参照、低遅延アプリ | 複雑な集計、長期トレンド分析 |
| アクセス形式 | 行キーによる特定のデータの読み書き | 列指向の全件スキャン・集計 |
| レイテンシ | シングルデジットms(極低) | 秒単位(中) |
| クエリ言語 | API(NoSQL方式) | 標準 SQL |
7. 設計のポイント:行キーのデザイン
Bigtableを利用する際、最も重要なのが「行キー(Row Key)」の設計です。株価データの場合、以下のような設計が一般的です。
[Ticker]#[Timestamp]
例:GOOG#1713883000この設計により、特定の銘柄のデータが物理的に近い場所に保存され、範囲指定のスキャンが効率化されます。
ただし、以下の2点に注意が必要です。
- タイムスタンプ先頭は禁止:タイムスタンプを先頭に持ってくると、常に最新時刻のデータが同じノードに集中する「ホットスポット」が発生します。
- 人気銘柄のホットスポットにも注意:
[Ticker]#[Timestamp]形式でも、GOOGやAAPLのような特定の銘柄への書き込みが一つのノードに集中する場合があります。書き込みが非常に高頻度になる場合は、ティッカーのハッシュ値をプレフィックスとして付与する「ソルティング」の採用も検討してください。
リアルタイムデータ処理の設計手法のまとめ
リアルタイムデータ処理では、「低レイテンシ」と「高スループット」を両立するためのアーキテクチャ設計が重要です。Pub/Subでデータを受け止め、Dataflowで処理・分配し、BigtableとBigQueryで用途別に使い分ける構成が基本となります。
特に、Hot(即時参照)とAnalytical(分析)を分離する設計が、性能と拡張性を大きく左右します。また、Bigtableの行キー設計など、細部のチューニングも全体性能に直結します。単一サービスに依存せず、役割ごとに最適なサービスを組み合わせることが成功の鍵です。
これにより、スケーラブルで高性能なリアルタイム基盤を実現できます。
まとめ
今回は、下記3点について説明しました。
- Pod Disruption Budget(PDB)の仕組みと実践ガイド
- GKEのアップグレード通知をリアルタイムで受け取る方法
- リアルタイムデータ処理の設計手法
本記事で扱った3つのテーマは、安定運用と高性能システムを実現するための中核要素です。
PDBにより可用性を担保し、アップグレード通知で運用をコントロールし、リアルタイム基盤で高スループット処理を実現します。これらは個別に最適化するだけでなく、全体として設計することが重要です。適切なサービスの組み合わせと設定により、予測可能でスケーラブルなシステムが構築できます。
試験対策にとどまらず、実務で通用する設計力として活用してください。
これからも、Macのシステムエンジニアとして、日々、習得した知識や経験を発信していきますので、是非、ブックマーク登録してくれると嬉しいです!
それでは、次回のブログで!

